





9 Practical Tactics to Turn Deepseek Right into A Sales Machine
페이지 정보

본문
 The Associated Press beforehand reported that DeepSeek has pc code that might ship some consumer login information to a Chinese state-owned telecommunications firm that has been barred from operating in the United States, in line with the security research agency Feroot. The web site of the Chinese synthetic intelligence firm DeepSeek, whose chatbot grew to become probably the most downloaded app in the United States, has computer code that might ship some person login info to a Chinese state-owned telecommunications firm that has been barred from operating within the United States, security researchers say. Available now on Hugging Face, the model provides users seamless access via net and API, and it seems to be probably the most superior large language model (LLMs) at present accessible in the open-supply panorama, in keeping with observations and assessments from third-occasion researchers. The DeepSeek mannequin license allows for industrial usage of the expertise beneath specific circumstances. This implies you need to use the expertise in commercial contexts, together with selling companies that use the model (e.g., software program-as-a-service). In a current post on the social network X by Maziyar Panahi, Principal AI/ML/Data Engineer at CNRS, the model was praised as "the world’s best open-source LLM" according to the DeepSeek team’s printed benchmarks.
The Associated Press beforehand reported that DeepSeek has pc code that might ship some consumer login information to a Chinese state-owned telecommunications firm that has been barred from operating in the United States, in line with the security research agency Feroot. The web site of the Chinese synthetic intelligence firm DeepSeek, whose chatbot grew to become probably the most downloaded app in the United States, has computer code that might ship some person login info to a Chinese state-owned telecommunications firm that has been barred from operating within the United States, security researchers say. Available now on Hugging Face, the model provides users seamless access via net and API, and it seems to be probably the most superior large language model (LLMs) at present accessible in the open-supply panorama, in keeping with observations and assessments from third-occasion researchers. The DeepSeek mannequin license allows for industrial usage of the expertise beneath specific circumstances. This implies you need to use the expertise in commercial contexts, together with selling companies that use the model (e.g., software program-as-a-service). In a current post on the social network X by Maziyar Panahi, Principal AI/ML/Data Engineer at CNRS, the model was praised as "the world’s best open-source LLM" according to the DeepSeek team’s printed benchmarks.
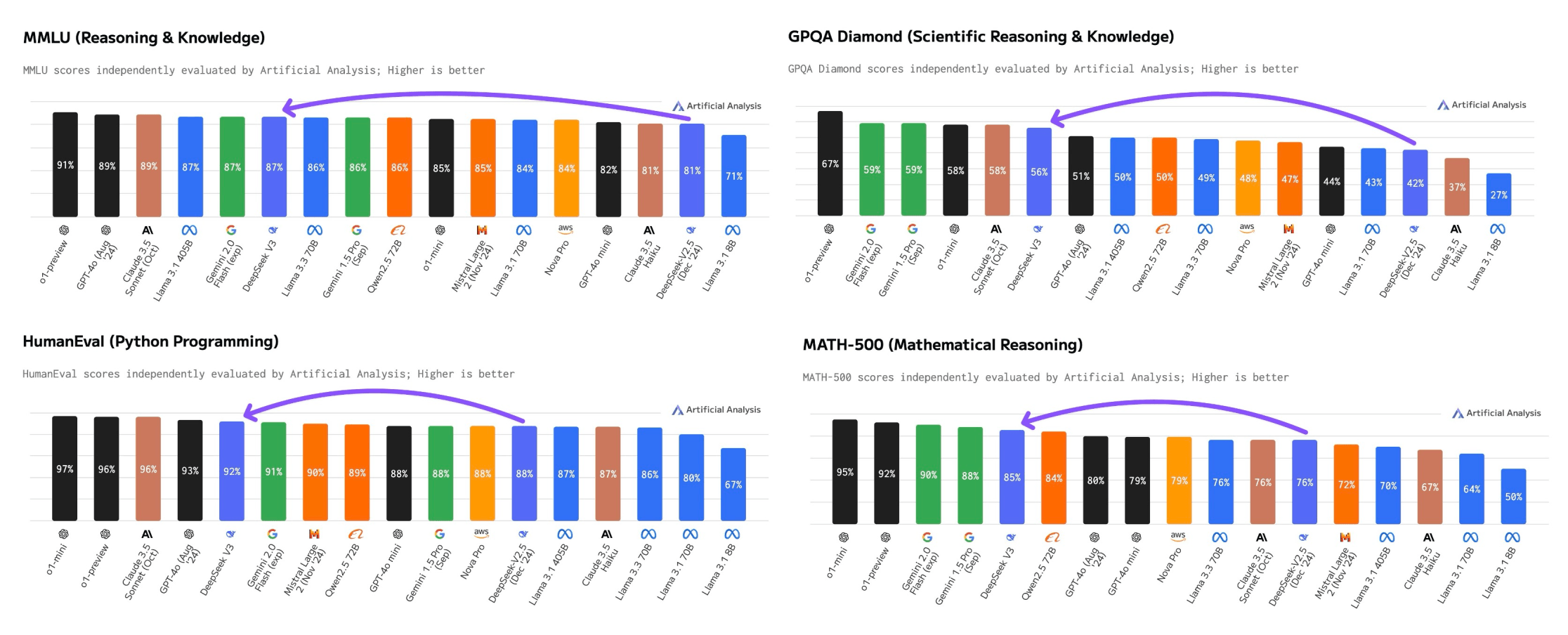 The reward for DeepSeek-V2.5 follows a nonetheless ongoing controversy round HyperWrite’s Reflection 70B, which co-founder and CEO Matt Shumer claimed on September 5 was the "the world’s high open-supply AI model," in keeping with his inside benchmarks, solely to see these claims challenged by independent researchers and the wider AI research group, who have up to now didn't reproduce the stated outcomes. In response to him DeepSeek-V2.5 outperformed Meta’s Llama 3-70B Instruct and Llama 3.1-405B Instruct, but clocked in at under efficiency in comparison with OpenAI’s GPT-4o mini, Claude 3.5 Sonnet, and OpenAI’s GPT-4o. V3 achieved GPT-4-stage efficiency at 1/11th the activated parameters of Llama 3.1-405B, with a complete training value of $5.6M. But such training knowledge shouldn't be obtainable in sufficient abundance. Meanwhile, DeepSeek also makes their fashions accessible for inference: that requires a whole bunch of GPUs above-and-past no matter was used for coaching. This has resulted in AI models that require far less computing energy than before. This compression allows for extra environment friendly use of computing assets, making the mannequin not only powerful but also highly economical when it comes to resource consumption.
The reward for DeepSeek-V2.5 follows a nonetheless ongoing controversy round HyperWrite’s Reflection 70B, which co-founder and CEO Matt Shumer claimed on September 5 was the "the world’s high open-supply AI model," in keeping with his inside benchmarks, solely to see these claims challenged by independent researchers and the wider AI research group, who have up to now didn't reproduce the stated outcomes. In response to him DeepSeek-V2.5 outperformed Meta’s Llama 3-70B Instruct and Llama 3.1-405B Instruct, but clocked in at under efficiency in comparison with OpenAI’s GPT-4o mini, Claude 3.5 Sonnet, and OpenAI’s GPT-4o. V3 achieved GPT-4-stage efficiency at 1/11th the activated parameters of Llama 3.1-405B, with a complete training value of $5.6M. But such training knowledge shouldn't be obtainable in sufficient abundance. Meanwhile, DeepSeek also makes their fashions accessible for inference: that requires a whole bunch of GPUs above-and-past no matter was used for coaching. This has resulted in AI models that require far less computing energy than before. This compression allows for extra environment friendly use of computing assets, making the mannequin not only powerful but also highly economical when it comes to resource consumption.
These outcomes were achieved with the model judged by GPT-4o, exhibiting its cross-lingual and cultural adaptability. These features along with basing on successful DeepSeekMoE architecture result in the next results in implementation. It’s interesting how they upgraded the Mixture-of-Experts architecture and attention mechanisms to new versions, making LLMs extra versatile, price-efficient, and capable of addressing computational challenges, handling lengthy contexts, and working in a short time. DeepSeek-V2.5’s structure contains key innovations, resembling Multi-Head Latent Attention (MLA), which considerably reduces the KV cache, thereby improving inference speed with out compromising on mannequin efficiency. Businesses can integrate the mannequin into their workflows for various duties, starting from automated buyer help and content generation to software growth and data evaluation. As businesses and builders seek to leverage AI extra effectively, DeepSeek-AI’s newest launch positions itself as a prime contender in each basic-function language tasks and specialized coding functionalities. The transfer indicators DeepSeek-AI’s dedication to democratizing access to superior AI capabilities.
Advanced customers and programmers can contact AI Enablement to entry many AI fashions via Amazon Web Services. In this article, I will describe the 4 principal approaches to building reasoning models, or how we can improve LLMs with reasoning capabilities. Frankly, I don’t assume it is the main cause. I believe any massive strikes now could be simply unimaginable to get proper. Now that is the world’s greatest open-supply LLM! That call was definitely fruitful, and now the open-supply household of fashions, including DeepSeek Coder, DeepSeek LLM, DeepSeekMoE, DeepSeek Chat-Coder-V1.5, DeepSeekMath, DeepSeek-VL, DeepSeek-V2, DeepSeek-Coder-V2, and DeepSeek-Prover-V1.5, will be utilized for a lot of purposes and is democratizing the usage of generative models. Testing DeepSeek-Coder-V2 on numerous benchmarks shows that DeepSeek-Coder-V2 outperforms most models, together with Chinese competitors. DeepSeek-V2.5 is optimized for a number of duties, together with writing, instruction-following, and advanced coding. By way of language alignment, DeepSeek-V2.5 outperformed GPT-4o mini and ChatGPT-4o-newest in inner Chinese evaluations. DeepSeek sends all the information it collects on Americans to servers in China, in accordance with the corporate's terms of service. Machine learning models can analyze affected person information to foretell disease outbreaks, recommend personalized therapy plans, and speed up the invention of latest medication by analyzing biological knowledge.
- 이전글Where Can You Find The Most Reliable ADHD In Adult Women Information? 25.03.03
- 다음글The 10 Most Scariest Things About Patio Doors Repairs Near Me 25.03.03
댓글목록
등록된 댓글이 없습니다.