





Quick-Observe Your Deepseek
페이지 정보

본문
![]() Yes, DeepSeek AI will be integrated into net, cellular, and enterprise functions via APIs and open-supply models. I am curious how properly the M-Chip Macbook Pros assist native AI models. I exploit VSCode with Codeium (not with an area model) on my desktop, and I'm curious if a Macbook Pro with a neighborhood AI mannequin would work properly sufficient to be useful for occasions when i don’t have web entry (or possibly as a alternative for paid AI fashions liek ChatGPT?). This model demonstrates how LLMs have improved for programming duties. 36Kr: Many startups have abandoned the broad path of only growing general LLMs due to main tech companies entering the sector. With sixteen you are able to do it but won’t have a lot left for different applications. While GPT-4o can support a much bigger context length, the price to process the enter is 8.Ninety two times larger. Depending on how a lot VRAM you have on your machine, you might be capable of reap the benefits of Ollama’s capability to run a number of fashions and handle a number of concurrent requests through the use of DeepSeek Coder 6.7B for autocomplete and Llama 3 8B for chat. Assuming you've a chat mannequin set up already (e.g. Codestral, Llama 3), you can keep this entire expertise local by offering a link to the Ollama README on GitHub and asking inquiries to learn more with it as context.
Yes, DeepSeek AI will be integrated into net, cellular, and enterprise functions via APIs and open-supply models. I am curious how properly the M-Chip Macbook Pros assist native AI models. I exploit VSCode with Codeium (not with an area model) on my desktop, and I'm curious if a Macbook Pro with a neighborhood AI mannequin would work properly sufficient to be useful for occasions when i don’t have web entry (or possibly as a alternative for paid AI fashions liek ChatGPT?). This model demonstrates how LLMs have improved for programming duties. 36Kr: Many startups have abandoned the broad path of only growing general LLMs due to main tech companies entering the sector. With sixteen you are able to do it but won’t have a lot left for different applications. While GPT-4o can support a much bigger context length, the price to process the enter is 8.Ninety two times larger. Depending on how a lot VRAM you have on your machine, you might be capable of reap the benefits of Ollama’s capability to run a number of fashions and handle a number of concurrent requests through the use of DeepSeek Coder 6.7B for autocomplete and Llama 3 8B for chat. Assuming you've a chat mannequin set up already (e.g. Codestral, Llama 3), you can keep this entire expertise local by offering a link to the Ollama README on GitHub and asking inquiries to learn more with it as context.
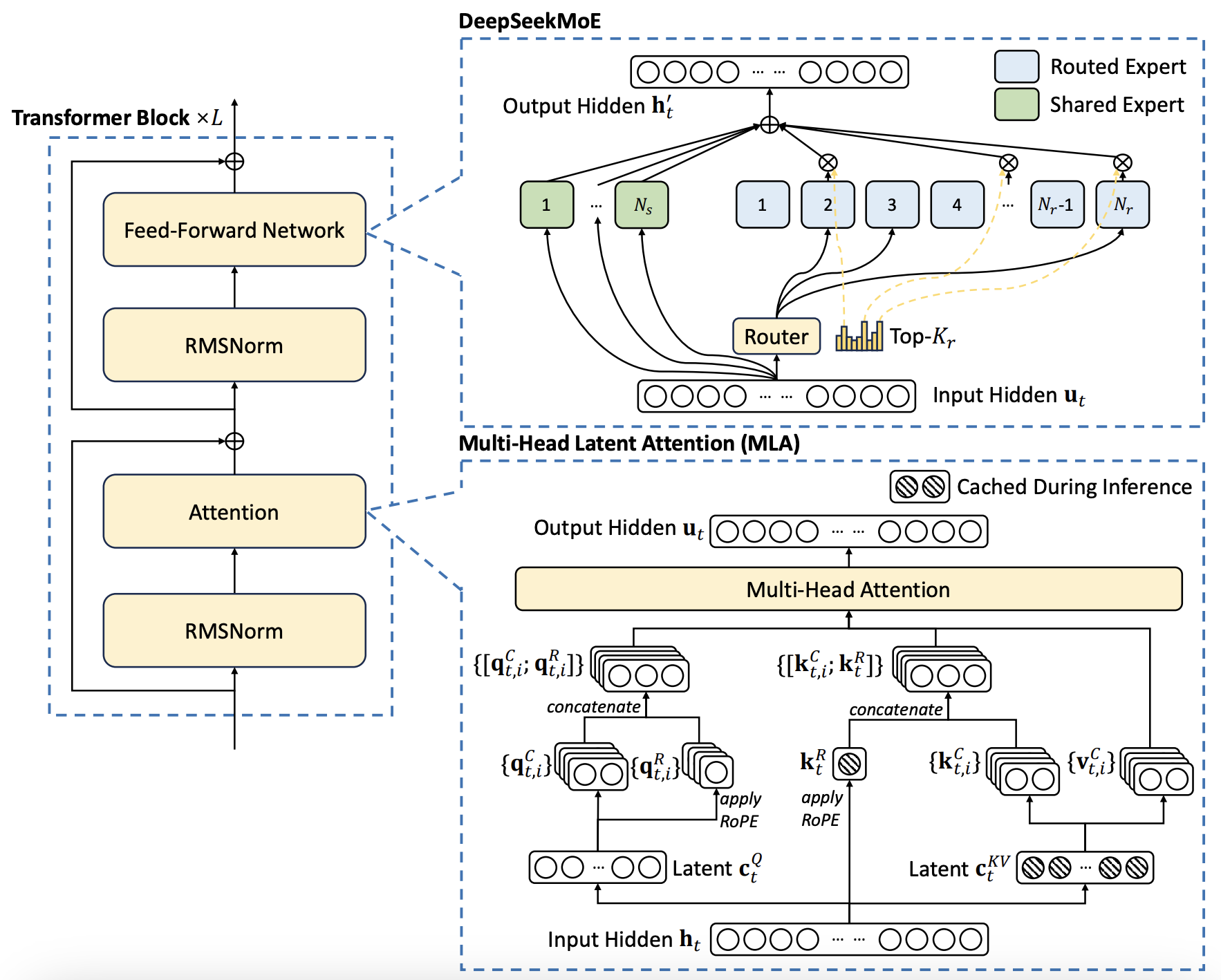 Assuming you might have a chat mannequin arrange already (e.g. Codestral, Llama 3), you possibly can keep this whole expertise native thanks to embeddings with Ollama and LanceDB. Because as our powers grow we are able to subject you to extra experiences than you have got ever had and you'll dream and these goals will be new. There’s plenty of YouTube videos on the topic with more particulars and demos of efficiency. Direct sales imply not sharing fees with intermediaries, leading to larger profit margins under the identical scale and performance. First, persons are speaking about it as having the same performance as OpenAI’s o1 mannequin. 3/4B) for easy F-I-M duties which might be often repetitive. I have an ‘old’ desktop at residence with an Nvidia card for extra complex tasks that I don’t wish to ship to Claude for no matter purpose. Although the total scope of DeepSeek's effectivity breakthroughs is nuanced and never but absolutely identified, it seems undeniable that they've achieved significant developments not purely through extra scale and extra information, but by way of clever algorithmic techniques.
Assuming you might have a chat mannequin arrange already (e.g. Codestral, Llama 3), you possibly can keep this whole expertise native thanks to embeddings with Ollama and LanceDB. Because as our powers grow we are able to subject you to extra experiences than you have got ever had and you'll dream and these goals will be new. There’s plenty of YouTube videos on the topic with more particulars and demos of efficiency. Direct sales imply not sharing fees with intermediaries, leading to larger profit margins under the identical scale and performance. First, persons are speaking about it as having the same performance as OpenAI’s o1 mannequin. 3/4B) for easy F-I-M duties which might be often repetitive. I have an ‘old’ desktop at residence with an Nvidia card for extra complex tasks that I don’t wish to ship to Claude for no matter purpose. Although the total scope of DeepSeek's effectivity breakthroughs is nuanced and never but absolutely identified, it seems undeniable that they've achieved significant developments not purely through extra scale and extra information, but by way of clever algorithmic techniques.
DeepSeek-Coder-V2, costing 20-50x occasions less than different fashions, represents a major upgrade over the unique DeepSeek-Coder, DeepSeek with more intensive training data, bigger and more environment friendly models, enhanced context dealing with, and DeepSeek Chat superior techniques like Fill-In-The-Middle and Reinforcement Learning. Microsoft, Google, and Amazon are clear winners but so are more specialized GPU clouds that can host models on your behalf. If you are into AI / LLM experimentation throughout a number of models, then it's essential to take a look. You may then use a remotely hosted or SaaS model for the opposite experience. With Amazon Bedrock Custom Model Import, you can import DeepSeek-R1-Distill fashions ranging from 1.5-70 billion parameters. US stocks dropped sharply Monday - and chipmaker Nvidia lost nearly $600 billion in market value - after a shock advancement from a Chinese artificial intelligence company, Free DeepSeek online, threatened the aura of invincibility surrounding America’s technology industry. DeepSeek has developed strategies to practice its fashions at a significantly lower price compared to business counterparts. Some market analysts have pointed to the Jevons Paradox, an financial concept stating that "increased efficiency in using a useful resource typically results in a better overall consumption of that useful resource." That does not mean the trade shouldn't at the identical time develop extra revolutionary measures to optimize its use of costly assets, from hardware to vitality.
By submitting Inputs to our Services, you represent and warrant that you have all rights, licenses, and permissions which can be vital for us to process the Inputs beneath our Terms. This implies, when it comes to computational energy alone, High-Flyer had secured its ticket to develop something like ChatGPT earlier than many main tech companies. Therefore, the developments of outdoors corporations such as DeepSeek are broadly part of Apple's continued involvement in AI research. The Chicoms Are Coming! 5️⃣ Speaking of Bluesky, Flashes, a pictures-solely app based mostly on Bluesky, is coming quickly. 4️⃣ Inoreader now helps Bluesky, so we will add search outcomes or follow users from an RSS reader. 3️⃣ Craft now helps the DeepSeek R1 local mannequin with out an internet connection. Each mannequin is pre-skilled on undertaking-stage code corpus by employing a window dimension of 16K and a extra fill-in-the-clean activity, to assist undertaking-stage code completion and infilling. This may increasingly take a while, depending on the size of the replace.
In case you have almost any questions with regards to in which and also how you can make use of DeepSeek v3, you possibly can contact us with the webpage.
- 이전글See What Situs Gotogel Terpercaya Tricks The Celebs Are Making Use Of 25.03.02
- 다음글Buy A Black German Shepherd: The Secret Life Of Buy A Black German Shepherd 25.03.02
댓글목록
등록된 댓글이 없습니다.