





10 Tricks To Grow Your Deepseek Ai News
페이지 정보

본문
 DeepSeek-R1 achieves state-of-the-art leads to numerous benchmarks and gives each its base fashions and distilled variations for neighborhood use. I needed to explore the type of UI/UX different LLMs could generate, so I experimented with a number of models using WebDev Arena. WebDev Arena is an open-supply benchmark evaluating AI capabilities in net growth, developed by LMArena. Additionally, the US Federal Trade Commission (FTC) has famous that AI instruments "are vulnerable to adversarial inputs or assaults that put private knowledge at risk." DeepSeek confirmed on Tuesday, January 28, that it was hit by a big-scale cyberattack, forcing it to pause new consumer signal-ups on its internet chatbot interface. Field, Hayden (January 18, 2024). "OpenAI broadcasts first partnership with a university". For each discipline, customers present a reputation, description, and its kind. After specifying the fields, users press the Extract Data button. Next, customers specify the fields they want to extract. I like that it added a sub-title to the web page Enter a URL and specify the fields to extract.
DeepSeek-R1 achieves state-of-the-art leads to numerous benchmarks and gives each its base fashions and distilled variations for neighborhood use. I needed to explore the type of UI/UX different LLMs could generate, so I experimented with a number of models using WebDev Arena. WebDev Arena is an open-supply benchmark evaluating AI capabilities in net growth, developed by LMArena. Additionally, the US Federal Trade Commission (FTC) has famous that AI instruments "are vulnerable to adversarial inputs or assaults that put private knowledge at risk." DeepSeek confirmed on Tuesday, January 28, that it was hit by a big-scale cyberattack, forcing it to pause new consumer signal-ups on its internet chatbot interface. Field, Hayden (January 18, 2024). "OpenAI broadcasts first partnership with a university". For each discipline, customers present a reputation, description, and its kind. After specifying the fields, users press the Extract Data button. Next, customers specify the fields they want to extract. I like that it added a sub-title to the web page Enter a URL and specify the fields to extract.
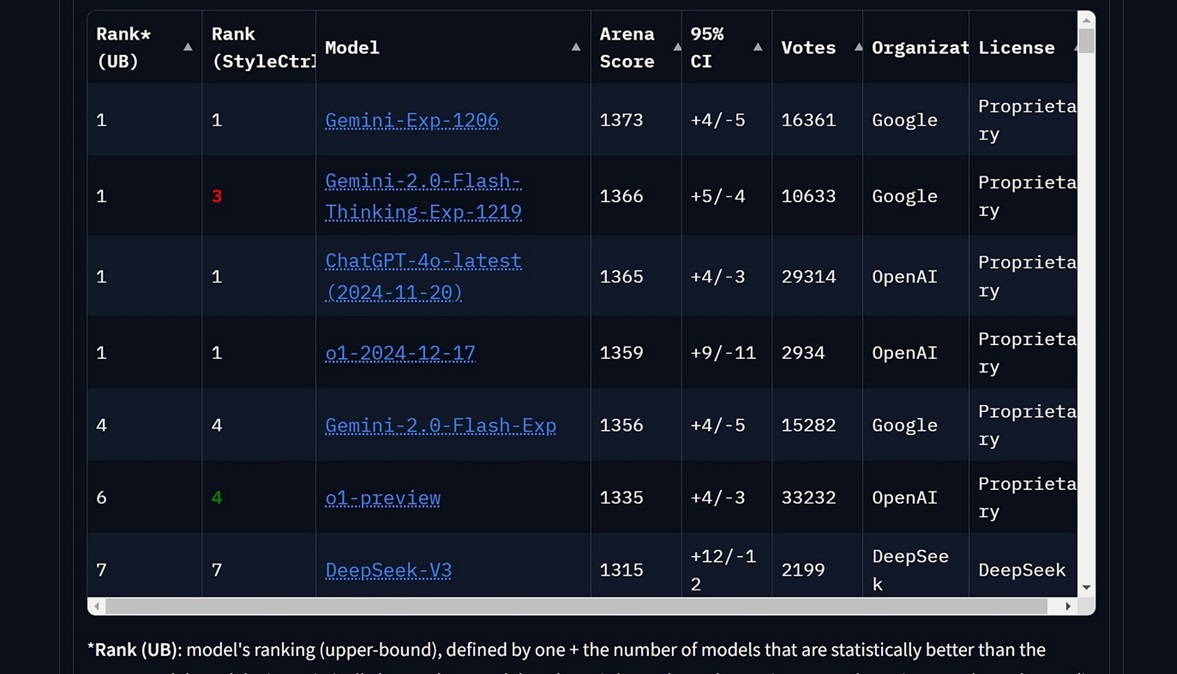 This assist keep away from lengthy form but when description is lengthy or we determine so as to add more fields then it should struggle. As you can see it generated a standard type with commonplace colour palette. 1-mini-2024-09-12 generated following UI. 1206 generated UI beneath. The implications of what DeepSeek has completed may ripple via the business. This problem isn't unique to DeepSeek - it represents a broader business concern as the road between human-generated and AI-generated content continues to blur. Chinese startup Free DeepSeek v3 is shaking up the worldwide AI landscape with its newest fashions, claiming performance comparable to or exceeding industry-leading US models at a fraction of the cost. To grasp this, first you need to know that AI mannequin costs may be divided into two categories: coaching costs (a one-time expenditure to create the model) and runtime "inference" costs - the price of chatting with the model. This platform permits you to run a prompt in an "AI battle mode," the place two random LLMs generate and render a Next.js React internet app. The two initiatives mentioned above demonstrate that attention-grabbing work on reasoning models is feasible even with restricted budgets. While no model delivered a flawless UX, each supplied insights into their design reasoning and capabilities.
This assist keep away from lengthy form but when description is lengthy or we determine so as to add more fields then it should struggle. As you can see it generated a standard type with commonplace colour palette. 1-mini-2024-09-12 generated following UI. 1206 generated UI beneath. The implications of what DeepSeek has completed may ripple via the business. This problem isn't unique to DeepSeek - it represents a broader business concern as the road between human-generated and AI-generated content continues to blur. Chinese startup Free DeepSeek v3 is shaking up the worldwide AI landscape with its newest fashions, claiming performance comparable to or exceeding industry-leading US models at a fraction of the cost. To grasp this, first you need to know that AI mannequin costs may be divided into two categories: coaching costs (a one-time expenditure to create the model) and runtime "inference" costs - the price of chatting with the model. This platform permits you to run a prompt in an "AI battle mode," the place two random LLMs generate and render a Next.js React internet app. The two initiatives mentioned above demonstrate that attention-grabbing work on reasoning models is feasible even with restricted budgets. While no model delivered a flawless UX, each supplied insights into their design reasoning and capabilities.
As a result, Thinking Mode is able to stronger reasoning capabilities in its responses than the Gemini 2.Zero Flash Experimental mannequin. Gemini 2.Zero Flash Thinking Mode is an experimental mannequin that’s trained to generate the "thinking process" the mannequin goes by way of as a part of its response. While frontier models have already been used as aids to human scientists, e.g. for brainstorming ideas, writing code, or prediction duties, they nonetheless conduct only a small a part of the scientific process. DeepSeek-Coder is one of AI mannequin by DeepSeek r1, which is focussed on writing codes. One notably fascinating strategy I came throughout last year is described within the paper O1 Replication Journey: A Strategic Progress Report - Part 1. Despite its title, the paper does not really replicate o1. Is Taiwan a part of China? Fortunately, early indications are that the Trump administration is considering further curbs on exports of Nvidia chips to China, in line with a Bloomberg report, with a focus on a potential ban on the H20s chips, a scaled down model for the China market. Frontier labs concentrate on FrontierMath and hard subsets of MATH: MATH degree 5, AIME, AMC10/AMC12.
Balancing safety and helpfulness has been a key focus throughout our iterative growth. The key concept of DualPipe is to overlap the computation and communication inside a pair of particular person forward and backward chunks. We will try a number of LLM models. Shortcut studying refers to the normal approach in instruction positive-tuning, the place models are trained utilizing only appropriate answer paths. To be particular, during MMA (Matrix Multiply-Accumulate) execution on Tensor Cores, intermediate results are accumulated utilizing the restricted bit width. As well as, DeepSeek's fashions are open source, meaning they are freely obtainable for anyone to make use of, modify, and distribute. DeepSeek Coder. Released in November 2023, this is the company's first open source mannequin designed particularly for coding-associated tasks. 200k normal tasks) for broader capabilities. Admittedly it’s just on this slender distribution of duties and not across the board… It’s not too bad for throwaway weekend initiatives, but nonetheless quite amusing. The TinyZero repository mentions that a research report continues to be work in progress, and I’ll definitely be conserving a watch out for additional particulars. While each approaches replicate methods from DeepSeek Chat-R1, one focusing on pure RL (TinyZero) and the other on pure SFT (Sky-T1), it could be fascinating to explore how these concepts might be prolonged additional.
- 이전글This Week's Most Popular Stories Concerning Motorcycle School 25.02.27
- 다음글التدريب الرياضي التعليم عن بعد - دبلوم عبر الإنترنيت 25.02.27
댓글목록
등록된 댓글이 없습니다.