





Stop Utilizing Create-react-app
페이지 정보

본문
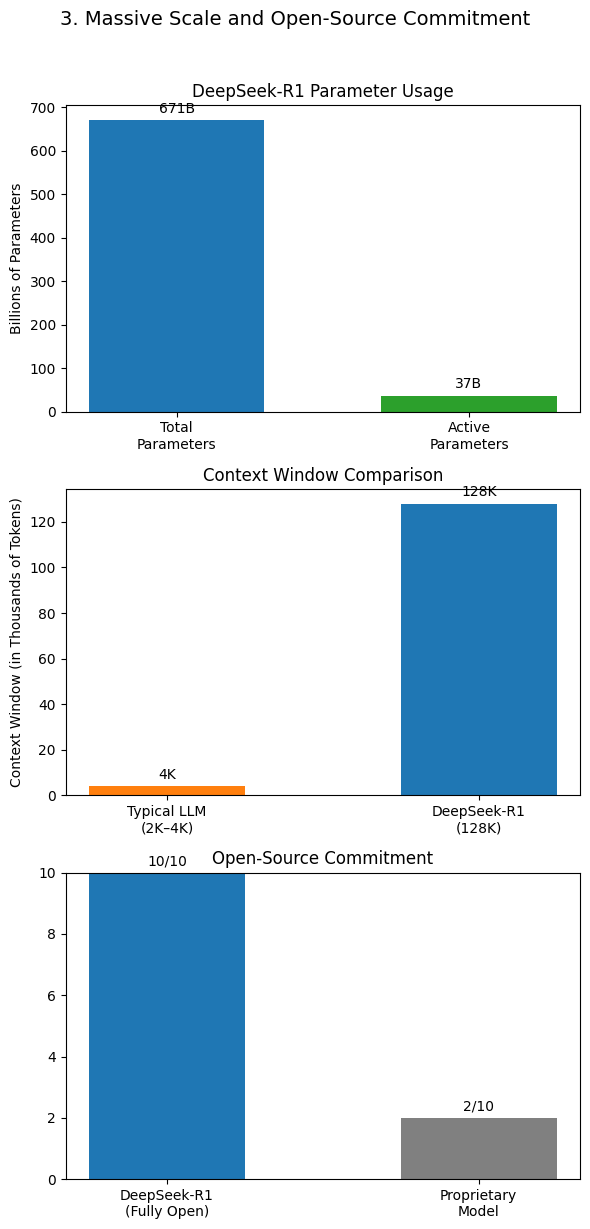
 Multi-head Latent Attention (MLA) is a new attention variant introduced by the deepseek ai group to improve inference efficiency. Its newest model was released on 20 January, rapidly impressing AI experts before it obtained the attention of the entire tech industry - and the world. It’s their latest mixture of specialists (MoE) model educated on 14.8T tokens with 671B complete and 37B energetic parameters. It’s simple to see the combination of strategies that result in massive performance good points compared with naive baselines. Why this matters: First, it’s good to remind ourselves that you are able to do a huge quantity of precious stuff with out chopping-edge AI. Programs, on the other hand, are adept at rigorous operations and might leverage specialised instruments like equation solvers for complicated calculations. But these instruments can create falsehoods and sometimes repeat the biases contained within their coaching information. DeepSeek was able to prepare the model utilizing a knowledge heart of Nvidia H800 GPUs in just around two months - GPUs that Chinese companies were not too long ago restricted by the U.S. Step 1: Collect code data from GitHub and apply the identical filtering guidelines as StarCoder Data to filter data. Given the issue issue (comparable to AMC12 and AIME exams) and the special format (integer answers only), we used a mixture of AMC, AIME, deep seek and Odyssey-Math as our drawback set, removing multiple-selection options and filtering out problems with non-integer solutions.
Multi-head Latent Attention (MLA) is a new attention variant introduced by the deepseek ai group to improve inference efficiency. Its newest model was released on 20 January, rapidly impressing AI experts before it obtained the attention of the entire tech industry - and the world. It’s their latest mixture of specialists (MoE) model educated on 14.8T tokens with 671B complete and 37B energetic parameters. It’s simple to see the combination of strategies that result in massive performance good points compared with naive baselines. Why this matters: First, it’s good to remind ourselves that you are able to do a huge quantity of precious stuff with out chopping-edge AI. Programs, on the other hand, are adept at rigorous operations and might leverage specialised instruments like equation solvers for complicated calculations. But these instruments can create falsehoods and sometimes repeat the biases contained within their coaching information. DeepSeek was able to prepare the model utilizing a knowledge heart of Nvidia H800 GPUs in just around two months - GPUs that Chinese companies were not too long ago restricted by the U.S. Step 1: Collect code data from GitHub and apply the identical filtering guidelines as StarCoder Data to filter data. Given the issue issue (comparable to AMC12 and AIME exams) and the special format (integer answers only), we used a mixture of AMC, AIME, deep seek and Odyssey-Math as our drawback set, removing multiple-selection options and filtering out problems with non-integer solutions.
 To train the mannequin, we wanted a suitable drawback set (the given "training set" of this competitors is too small for tremendous-tuning) with "ground truth" solutions in ToRA format for supervised fantastic-tuning. To run regionally, DeepSeek-V2.5 requires BF16 format setup with 80GB GPUs, with optimum performance achieved utilizing 8 GPUs. Computational Efficiency: The paper doesn't present detailed info in regards to the computational sources required to train and run DeepSeek-Coder-V2. Other than customary techniques, vLLM provides pipeline parallelism allowing you to run this model on multiple machines related by networks. 4. They use a compiler & high quality model & heuristics to filter out garbage. By the way, is there any specific use case in your thoughts? The accessibility of such superior models may result in new applications and use instances throughout numerous industries. Claude 3.5 Sonnet has shown to be probably the greatest performing models out there, and is the default mannequin for our free deepseek and Pro customers. We’ve seen improvements in overall user satisfaction with Claude 3.5 Sonnet throughout these users, so on this month’s Sourcegraph release we’re making it the default model for chat and prompts.
To train the mannequin, we wanted a suitable drawback set (the given "training set" of this competitors is too small for tremendous-tuning) with "ground truth" solutions in ToRA format for supervised fantastic-tuning. To run regionally, DeepSeek-V2.5 requires BF16 format setup with 80GB GPUs, with optimum performance achieved utilizing 8 GPUs. Computational Efficiency: The paper doesn't present detailed info in regards to the computational sources required to train and run DeepSeek-Coder-V2. Other than customary techniques, vLLM provides pipeline parallelism allowing you to run this model on multiple machines related by networks. 4. They use a compiler & high quality model & heuristics to filter out garbage. By the way, is there any specific use case in your thoughts? The accessibility of such superior models may result in new applications and use instances throughout numerous industries. Claude 3.5 Sonnet has shown to be probably the greatest performing models out there, and is the default mannequin for our free deepseek and Pro customers. We’ve seen improvements in overall user satisfaction with Claude 3.5 Sonnet throughout these users, so on this month’s Sourcegraph release we’re making it the default model for chat and prompts.
BYOK customers ought to test with their supplier in the event that they assist Claude 3.5 Sonnet for their specific deployment atmosphere. To assist the research community, we have open-sourced DeepSeek-R1-Zero, DeepSeek-R1, and 6 dense fashions distilled from DeepSeek-R1 based mostly on Llama and Qwen. Cody is constructed on model interoperability and we purpose to provide access to one of the best and latest fashions, and right now we’re making an update to the default fashions provided to Enterprise prospects. Users should upgrade to the latest Cody model of their respective IDE to see the benefits. To harness the benefits of each methods, we carried out this system-Aided Language Models (PAL) or extra precisely Tool-Augmented Reasoning (ToRA) method, originally proposed by CMU & Microsoft. And we hear that some of us are paid greater than others, according to the "diversity" of our dreams. Most GPTQ recordsdata are made with AutoGPTQ. If you are working VS Code on the same machine as you might be hosting ollama, you might attempt CodeGPT however I could not get it to work when ollama is self-hosted on a machine remote to where I used to be running VS Code (well not without modifying the extension recordsdata). And I'll do it once more, and once more, in each mission I work on still using react-scripts.
Like any laboratory, DeepSeek absolutely has different experimental items going in the background too. This could have significant implications for fields like mathematics, computer science, and past, by serving to researchers and problem-solvers discover options to challenging issues more efficiently. The AIS, very like credit score scores within the US, is calculated utilizing quite a lot of algorithmic elements linked to: question security, patterns of fraudulent or criminal behavior, tendencies in usage over time, compliance with state and federal regulations about ‘Safe Usage Standards’, and a wide range of other components. Usage restrictions embody prohibitions on army functions, dangerous content technology, and exploitation of weak groups. The licensing restrictions mirror a rising consciousness of the potential misuse of AI applied sciences. Future outlook and potential affect: DeepSeek-V2.5’s launch may catalyze further developments in the open-supply AI group and affect the broader AI industry. Expert recognition and reward: The new model has received important acclaim from trade professionals and AI observers for its performance and capabilities.
If you beloved this short article and you would like to get a lot more facts relating to ديب سيك مجانا kindly pay a visit to our own internet site.
- 이전글5 Killer Quora Answers On Double Glazing Deals Near Me 25.02.01
- 다음글Five Killer Quora Answers To Pushchair Twin 25.02.01
댓글목록
등록된 댓글이 없습니다.