





What The In-Crowd Won't Inform you About Deepseek
페이지 정보

본문
 If you're a programmer or researcher who want to access DeepSeek in this fashion, please attain out to AI Enablement. It undoubtedly seems prefer it. The top result's software that may have conversations like an individual or predict folks's buying habits. If speaking about weights, weights you possibly can publish immediately. Second, R1 - like all of DeepSeek’s models - has open weights (the issue with saying "open source" is that we don’t have the info that went into creating it). The top of the "best open LLM" - the emergence of different clear dimension categories for open models and why scaling doesn’t handle everyone within the open model audience. To handle this, the team used a short stage of SFT to stop the "chilly start" downside of RL. To handle these points and additional enhance reasoning efficiency, we introduce DeepSeek-R1, which includes a small amount of chilly-begin knowledge and a multi-stage training pipeline. A particularly intriguing phenomenon noticed during the coaching of DeepSeek-R1-Zero is the prevalence of an "aha moment". This moment is just not only an "aha moment" for the mannequin but in addition for the researchers observing its habits.
If you're a programmer or researcher who want to access DeepSeek in this fashion, please attain out to AI Enablement. It undoubtedly seems prefer it. The top result's software that may have conversations like an individual or predict folks's buying habits. If speaking about weights, weights you possibly can publish immediately. Second, R1 - like all of DeepSeek’s models - has open weights (the issue with saying "open source" is that we don’t have the info that went into creating it). The top of the "best open LLM" - the emergence of different clear dimension categories for open models and why scaling doesn’t handle everyone within the open model audience. To handle this, the team used a short stage of SFT to stop the "chilly start" downside of RL. To handle these points and additional enhance reasoning efficiency, we introduce DeepSeek-R1, which includes a small amount of chilly-begin knowledge and a multi-stage training pipeline. A particularly intriguing phenomenon noticed during the coaching of DeepSeek-R1-Zero is the prevalence of an "aha moment". This moment is just not only an "aha moment" for the mannequin but in addition for the researchers observing its habits.
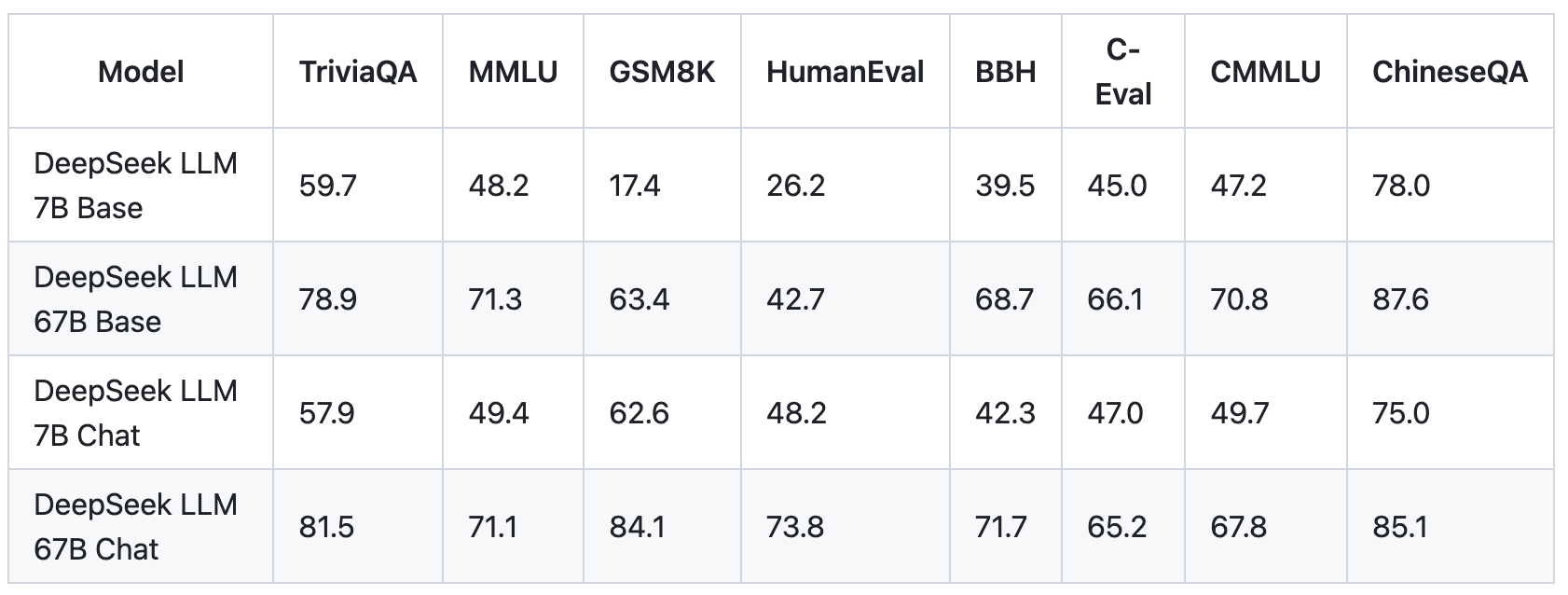 The "aha moment" serves as a powerful reminder of the potential of RL to unlock new levels of intelligence in synthetic programs, paving the best way for more autonomous and adaptive models sooner or later. DeepSeek doesn’t disclose the datasets or coaching code used to practice its fashions. Here again it seems plausible that DeepSeek benefited from distillation, significantly in phrases of training R1. Whether or not they generalize beyond their RL training is a trillion-dollar question. This also explains why Softbank (and whatever buyers Masayoshi Son brings collectively) would offer the funding for OpenAI that Microsoft will not: the idea that we are reaching a takeoff point the place there will the truth is be real returns in the direction of being first. Impact: Investors and analysts benefit from quicker insights, enabling better-informed resolution-making and proactive methods. Beyond the essential structure, we implement two additional methods to further improve the mannequin capabilities. It underscores the power and wonder of reinforcement studying: relatively than explicitly educating the mannequin on how to unravel a problem, we merely present it with the proper incentives, and it autonomously develops superior downside-solving strategies.
The "aha moment" serves as a powerful reminder of the potential of RL to unlock new levels of intelligence in synthetic programs, paving the best way for more autonomous and adaptive models sooner or later. DeepSeek doesn’t disclose the datasets or coaching code used to practice its fashions. Here again it seems plausible that DeepSeek benefited from distillation, significantly in phrases of training R1. Whether or not they generalize beyond their RL training is a trillion-dollar question. This also explains why Softbank (and whatever buyers Masayoshi Son brings collectively) would offer the funding for OpenAI that Microsoft will not: the idea that we are reaching a takeoff point the place there will the truth is be real returns in the direction of being first. Impact: Investors and analysts benefit from quicker insights, enabling better-informed resolution-making and proactive methods. Beyond the essential structure, we implement two additional methods to further improve the mannequin capabilities. It underscores the power and wonder of reinforcement studying: relatively than explicitly educating the mannequin on how to unravel a problem, we merely present it with the proper incentives, and it autonomously develops superior downside-solving strategies.
This habits isn't only a testament to the model’s growing reasoning abilities but in addition a captivating example of how reinforcement learning can lead to unexpected and subtle outcomes. The traditional example is AlphaGo, the place DeepMind gave the mannequin the principles of Go with the reward perform of winning the game, after which let the model figure the whole lot else by itself. DeepSeek gave the model a set of math, code, and logic questions, and set two reward functions: one for the correct reply, and one for the suitable format that utilized a considering course of. It’s one model that does all the things really well and it’s superb and all these different things, and gets closer and closer to human intelligence. R1-Zero, nevertheless, drops the HF part - it’s simply reinforcement studying. The eye part employs 4-method Tensor Parallelism (TP4) with Sequence Parallelism (SP), combined with 8-method Data Parallelism (DP8). The structure, akin to LLaMA, employs auto-regressive transformer decoder fashions with distinctive attention mechanisms.
This quarter, R1 will be one of many flagship models in our AI Studio launch, alongside different main models. That is one of the most highly effective affirmations but of The Bitter Lesson: you don’t need to show the AI find out how to motive, you may just give it sufficient compute and data and it'll educate itself! Reinforcement learning is a way the place a machine learning model is given a bunch of data and a reward function. This sounds a lot like what OpenAI did for o1: DeepSeek began the model out with a bunch of examples of chain-of-thought pondering so it might learn the proper format for human consumption, after which did the reinforcement studying to boost its reasoning, together with numerous modifying and refinement steps; the output is a mannequin that seems to be very aggressive with o1. Which means that instead of paying OpenAI to get reasoning, you'll be able to run R1 on the server of your alternative, and even regionally, at dramatically decrease value. Wait, you haven’t even talked about R1 but.
If you beloved this article and you would like to obtain more data about شات DeepSeek kindly pay a visit to our own internet site.
- 이전글12 Companies Leading The Way In Crypto Casino 25.02.09
- 다음글What's The Current Job Market For Composite Door Paint Repair Professionals? 25.02.09
댓글목록
등록된 댓글이 없습니다.