





Learn the way I Cured My Deepseek In 2 Days
페이지 정보

본문
 When the BBC asked the app what occurred at Tiananmen Square on 4 June 1989, DeepSeek didn't give any particulars about the massacre, a taboo topic in China. If you’re feeling overwhelmed by election drama, try our newest podcast on making clothes in China. Impressive speed. Let's look at the modern structure below the hood of the most recent models. Combination of these improvements helps DeepSeek-V2 obtain special options that make it much more aggressive among other open fashions than earlier variations. I believe what has perhaps stopped extra of that from happening immediately is the businesses are still doing effectively, especially OpenAI. Listed below are my ‘top 3’ charts, beginning with the outrageous 2024 expected LLM spend of US$18,000,000 per company. By incorporating 20 million Chinese a number of-alternative questions, DeepSeek LLM 7B Chat demonstrates improved scores in MMLU, C-Eval, and CMMLU. Scores based mostly on inside take a look at sets:decrease percentages indicate less affect of security measures on normal queries. The Hungarian National High school Exam serves as a litmus test for mathematical capabilities. These methods improved its performance on mathematical benchmarks, attaining pass charges of 63.5% on the excessive-college stage miniF2F take a look at and 25.3% on the undergraduate-degree ProofNet check, setting new state-of-the-artwork results.
When the BBC asked the app what occurred at Tiananmen Square on 4 June 1989, DeepSeek didn't give any particulars about the massacre, a taboo topic in China. If you’re feeling overwhelmed by election drama, try our newest podcast on making clothes in China. Impressive speed. Let's look at the modern structure below the hood of the most recent models. Combination of these improvements helps DeepSeek-V2 obtain special options that make it much more aggressive among other open fashions than earlier variations. I believe what has perhaps stopped extra of that from happening immediately is the businesses are still doing effectively, especially OpenAI. Listed below are my ‘top 3’ charts, beginning with the outrageous 2024 expected LLM spend of US$18,000,000 per company. By incorporating 20 million Chinese a number of-alternative questions, DeepSeek LLM 7B Chat demonstrates improved scores in MMLU, C-Eval, and CMMLU. Scores based mostly on inside take a look at sets:decrease percentages indicate less affect of security measures on normal queries. The Hungarian National High school Exam serves as a litmus test for mathematical capabilities. These methods improved its performance on mathematical benchmarks, attaining pass charges of 63.5% on the excessive-college stage miniF2F take a look at and 25.3% on the undergraduate-degree ProofNet check, setting new state-of-the-artwork results.
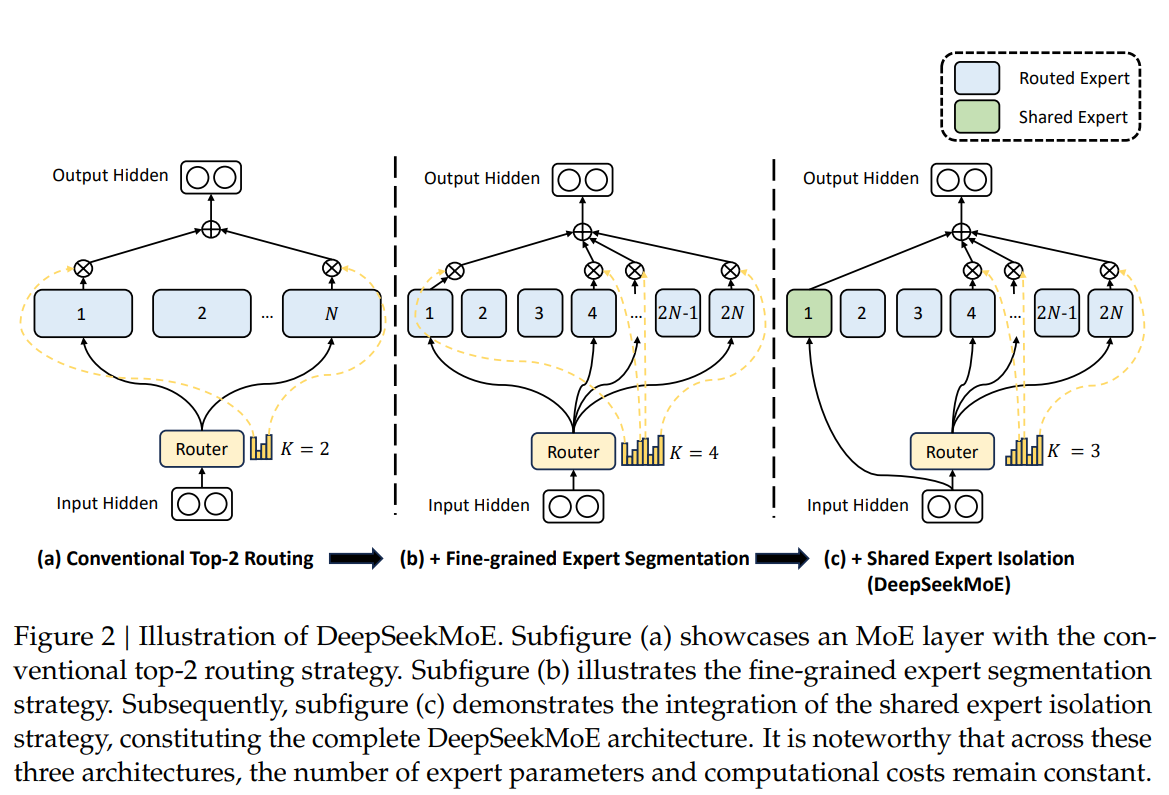
But beneath all of this I have a sense of lurking horror - AI programs have obtained so helpful that the factor that will set people apart from each other shouldn't be specific laborious-won skills for utilizing AI methods, however rather simply having a high level of curiosity and company. Shared skilled isolation: Shared consultants are specific experts that are at all times activated, no matter what the router decides. Unlike Qianwen and Baichuan, DeepSeek and Yi are more "principled" of their respective political attitudes. The slower the market moves, the more an advantage. To further investigate the correlation between this flexibility and the benefit in mannequin efficiency, we additionally design and validate a batch-wise auxiliary loss that encourages load balance on every coaching batch as a substitute of on every sequence. The freshest mannequin, launched by DeepSeek in August 2024, is an optimized version of their open-supply mannequin for theorem proving in Lean 4, DeepSeek-Prover-V1.5. DeepSeekMoE is a sophisticated version of the MoE architecture designed to improve how LLMs handle advanced tasks. This time builders upgraded the previous version of their Coder and now DeepSeek-Coder-V2 supports 338 languages and 128K context size. I doubt that LLMs will substitute developers or make someone a 10x developer.
I feel this is a very good read for many who want to grasp how the world of LLMs has modified prior to now yr. It’s been only a half of a 12 months and DeepSeek AI startup already significantly enhanced their fashions. This strategy allows fashions to handle totally different aspects of knowledge extra successfully, enhancing efficiency and scalability in giant-scale tasks. This enables the mannequin to process info sooner and with much less memory with out shedding accuracy. By having shared specialists, the model doesn't must store the same info in a number of locations. Risk of shedding information whereas compressing data in MLA. Faster inference because of MLA. DeepSeek-V2 is a state-of-the-art language model that uses a Transformer architecture combined with an revolutionary MoE system and a specialised consideration mechanism known as Multi-Head Latent Attention (MLA). DeepSeek-V2 introduces Multi-Head Latent Attention (MLA), a modified attention mechanism that compresses the KV cache into a a lot smaller type. Multi-Head Latent Attention (MLA): In a Transformer, attention mechanisms help the model give attention to probably the most related components of the enter. This can be a common use mannequin that excels at reasoning and multi-flip conversations, with an improved give attention to longer context lengths. At the end of last week, in line with CNBC reporting, the US Navy issued an alert to its personnel warning them not to use DeepSeek’s companies "in any capability." The e-mail stated Navy members of staff shouldn't download, set up, or use the mannequin, and raised considerations of "potential security and ethical" points.
Should you loved this informative article along with you desire to get more information about ديب سيك i implore you to check out our web-site.
- 이전글تاريخ البيمارستانات في الإسلام/في بيمارستانات البلاد الإسلامية على التفصيل 25.02.01
- 다음글لسان العرب : طاء - 25.02.01
댓글목록
등록된 댓글이 없습니다.